Reading the title, one might be confused as to whether or not I had a stroke when thinking of it, but I assure you that it will make sense.
A few weeks ago, around mid-May, I had the opportunity to attend the Converge Conference for the third year in a row. Converge is a smaller security convention that grew of the Detroit B-Sides (yes, I know, wrong order, but that’s part of what makes it fun). It brings together infosec people from Detroit, Windsor, and their respective metro areas. Occasionally we get people from all the way out in Chicago join in as well.
I had a blast at Converge this year just like the years before spending my time split between volunteering and attending the conference. This year was a particularly good year, lots of good talks, workshops, sponsor presence, a really good CTF event, and of course socializing. I highly recommend anyone in the Detroit-Windsor area to attend if they can. Many brilliant and well-connected people partake in both organizing and attending the convention. It can be a great experience for both students like myself and fulltime practitioners of the field. I recall a particularly fun talk by a good friend Kent Gruber who had spent some time analyzing Roku devices and ways in which they could be exploited.
Going to Converge, I’d always attended the talks and tried to use them as opportunities for networking. This year I decided I would attend a workshop as well to try and learn a bit more. The hard part was choosing which to attend as there were seven, and at least based on titles, they all seemed pretty interesting. I ended up picking one titled “Mo’ Data Mo’ Problems” hosted by my good friend and fellow #misec member Bryan Britten. I will admit, going into it, I wasn’t sure how much I’d gain from it as the two tools/languages(?) used were R and SQL. Up to that point my experience with SQL involved a few small projects for school and I’d never touched R. It turns out that it’s not as hard as I assumed it would be.
The workshop consisted of Bryan having us go through the data which was anonymized network data (here’s a link to his github page for that data) and trying to gain valuable information from it. At first it was explained what the anonymization process would be like and how one would do that using SQL. He then had us look at the data and try to answer questions based on it. The key takeaway that I had from this all was that the trick in data science and visualization is to correctly “translate” what the business request is to a database query. Throughout the workshop we answered various questions such as “How do we know what day of the week it is without knowing when the starting point of this data capture is?” That was a really fun question to answer. It ended up being done using a JOIN query to pull from the number of authentications made and the time since the start. The output was then graphed using R. Despite having no concrete initial date, when the graph was complete, it was very obvious what the days of the week were as there would be 2 day periods where the graph dipped down noticeably indicating a weekend.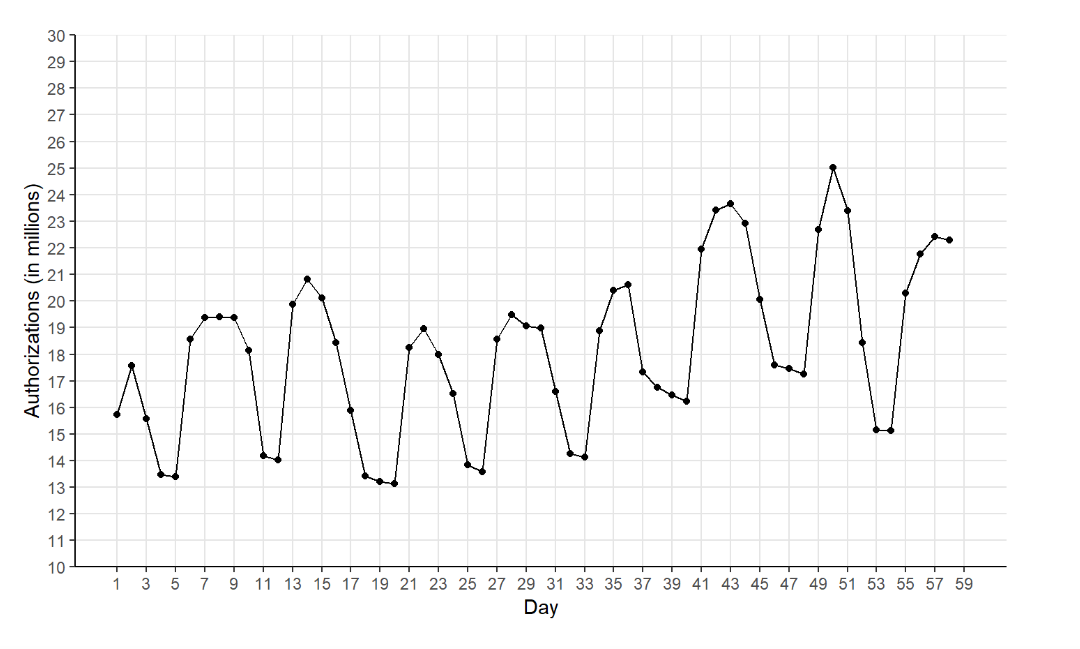
Aside from that, R and its merits were discussed, like how it is really good at visualization compared to many so-called visualization tools which have major limits on how the data output looks. Bryan again made a point to re-iterate how important it is for someone going through data like that to be able to properly understand how to visualize business requests as database queries.
Overall, I learned a lot from that convention and I look forward to next year. If you’ve been there, I hope to see you there again next year, and if you’ve never been, try to come out. There’s usually an afterparty which is also really fun.